虚拟电厂开发方向建议(11)基于联邦学习的隐私保护数据共享方案
 COVER · energy
COVER · energy核心价值:从“数据集中共享”到“隐私保护下的联合价值挖掘”
虚拟电厂涉及多方数据共享的场景下,利用联邦学习技术,实现数据在不离开本地的情况下进行联合建模与分析,保护各方的数据隐私,适配多主体数据隔离场景、避免数据泄露风险,突破传统数据集中上传才能联合建模局限——构建“本地训练-参数共享-全局聚合”的联邦学习框架。方案支持“横向联邦(同类型VPP)、纵向联邦(不同角色主体)”双模式,适配从日常数据协同到市场联合参与的全场景数据共享需求。
开发关键:隐私保护与联合建模双平衡
(1)数据源与共享场景梳理
明确需联合建模的核心数据与场景,避免无差别联邦导致资源浪费:
- 基础必选共享场景(核心隐私需求,优先覆盖)
聚焦三类高隐私风险的共享场景:
- 多VPP联合预测场景:如社区VPP间联合构建区域负荷预测模型、工商业VPP间联合生成电力市场竞价策略模型,需共享的本地数据包括各VPP的历史负荷、新能源出力、电价响应数据(均为非敏感聚合数据,不包含用户个体明细);
- 跨主体协同调度场景:如VPP与电动汽车运营商、智能楼宇物业协同优化能源调度,VPP需共享本地新能源预测数据,运营商/物业需共享充电需求、楼宇负荷数据,此类数据涉及各主体商业隐私(如充电定价策略、楼宇租金关联的用电成本);
- 监管与合规场景:如VPP向电网调度中心、碳监管平台提供数据支持,需在保护VPP运营数据(如收益明细)的前提下,共享合规所需的聚合指标(如总碳排放量、新能源消纳量)。
- 需保护的本地数据类型(按隐私等级分级)
数据需按敏感度分类处理将各VPP本地数据分为三级,确保隐私保护精准落地:
- 高敏感数据:含居民用户用电明细(如某家庭每日用电曲线)、工商业生产负荷数据(如生产线启停时段)、VPP市场竞价策略(如现货报价区间),此类数据严禁离开本地,仅允许通过联邦学习传递加密后的模型参数;
- 中敏感数据:含VPP聚合负荷(如某社区 hourly 总负荷)、新能源出力统计(如光伏日发电量),此类数据可通过“差分隐私”处理后参与联合建模(如添加微小噪声避免反向推导),平衡隐私与建模精度;
- 低敏感数据:含VPP设备类型(如光伏板型号)、区域气象均值(如日均光照时长),此类数据可直接共享,降低联邦学习复杂度。
(2)联邦学习架构与流程设计
算法需适配开发能力、避免过度技术堆砌”的原则,结合联邦学习技术应用的要求,提供基础款与进阶款两类架构方案,平衡隐私保护强度与开发可行性:
- 基础款架构
采用“横向联邦学习+参数明文聚合”的轻量化方案,适配同类型VPP(如多个社区VPP、多个工商业VPP)的联合建模,降低开发门槛:
- 架构设计:采用“中心服务器+本地节点”的简化架构——中心服务器负责参数初始化与聚合,各VPP作为本地节点,基于自身数据训练模型(如负荷预测模型),仅上传模型参数(如权重、偏置)至中心;
- 核心流程:①中心服务器下发初始模型参数;②各VPP本地训练(用PyTorch/TensorFlow加载本地数据,训练1-3个epoch);③本地节点上传参数至中心;④中心采用“加权平均”聚合参数(权重按各VPP数据量占比设定);⑤中心下发聚合后参数至各节点,重复迭代至模型收敛;
- 隐私增强:参数传输采用HTTPS加密,中心服务器仅存储参数不保留数据,工具选型为PySyft(轻量化联邦学习框架)、TensorFlow Federated(开源组件),降低开发成本。
- 进阶款架构
采用“纵向联邦学习/联邦强化学习+同态加密”的方案,适配跨类型VPP、跨主体协同的复杂场景,提升隐私保护强度与建模效果:
- 架构设计:针对跨主体场景(如VPP+充电桩运营商)采用纵向联邦——VPP拥有“负荷数据”,运营商拥有“充电需求数据”,双方基于隐私ID对齐样本(如时间戳),分别训练模型不同层,仅传递中间层加密结果;针对跨区域VPP协同调度,采用联邦强化学习——各VPP本地训练调度策略模型,上传策略梯度至中心,中心聚合后下发全局梯度;
- 核心流程:①隐私样本对齐(用安全多方计算技术匹配双方共同样本,不泄露非交集数据);②本地模型训练(VPP训练负荷预测层,运营商训练充电需求层);③加密参数交互(用Paillier同态加密处理中间参数,防止拦截破解);④全局模型生成(合并各层参数,形成联合模型);
- 容错机制:当某VPP节点离线时,中心自动采用“历史参数替代”或“减少该节点权重”,确保联邦训练不中断。
(3)数据对齐与模型优化
数据融合需提升精度、避免资源浪费,结合联邦学习“数据非独立同分布(Non-IID)”的特点,设计针对性优化措施,解决“数据分布不均导致模型精度低”的问题:
- 隐私保护下的数据对齐:多源数据格式差异采用“隐私保护的特征对齐”技术——各VPP本地对数据进行标准化处理(如将负荷数据归一化至[0,1]),通过“加密字典映射”统一特征名称(如“光伏出力”统一为“PV_output”),避免直接传输原始数据进行格式对齐,保障隐私的同时提升数据一致性;
- 模型精度优化:针对联邦学习中“数据分布不均”的痛点,基础款采用“加权联邦平均”(数据量多的VPP参数权重更高),进阶款引入“迁移学习”(用同类VPP的预训练模型初始化本地模型,减少Non-IID影响),数据稀缺场景用迁移学习”的思路,确保联合模型精度不低于集中式建模(误差差距控制在5%以内);
- 通信效率优化:实时场景需低延迟的需求,采用“参数压缩”(如量化参数精度从32位降至16位)、“稀疏更新”(仅上传变化超过阈值的参数),将参数传输量降低60%-70%,避免通信延迟影响联邦训练效率。
技术选型与落地验证
(1)核心工具选型
- 联邦学习框架:基础款用PySyft(轻量级,支持Python端快速开发)、TensorFlow Federated(Google开源,适配多端部署),进阶款用FedML(支持纵向联邦、联邦强化学习);
- 隐私保护工具:用Paillier同态加密(参数加密)、差分隐私库(如TensorFlow Privacy,添加噪声保护);
- 数据处理与可视化:用Pandas(本地数据清洗)、Matplotlib(展示本地训练损失与全局精度对比)。
(2)落地验证方案:分场景测试
- 场景1:社区VPP联合负荷预测(3个社区VPP,各含200户居民)
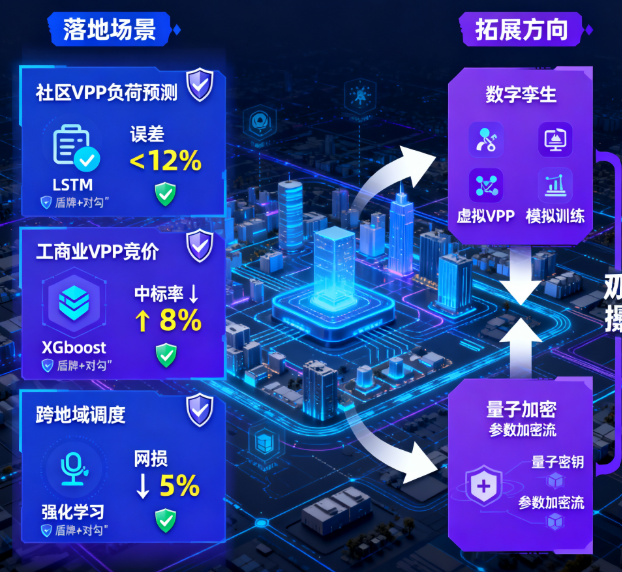
验证目标:①隐私保护(居民用电明细未离开本地,反向推导用户数据成功率=0);②模型精度(联邦模型负荷预测误差<12%,与集中式模型误差差距<3%);③通信效率(单次参数传输量<10MB,训练总耗时<2小时);
验证流程:各社区VPP用本地居民负荷数据训练LSTM模型,通过PySyft实现参数共享与聚合,对比“联邦模型”与“单社区模型”的精度,测试数据泄露风险(如尝试从聚合参数反推用户用电),输出“隐私测试报告+精度对比表”。
- 场景2:工商业VPP联合竞价策略建模(2个工商业VPP,含生产负荷数据)
验证目标:①隐私保护(生产负荷数据、竞价报价策略未泄露,第三方无法从参数中提取商业信息);②市场收益(联邦模型生成的竞价策略,中标率较单VPP模型提升≥8%);③合规性(符合数据本地化存储法规,数据未跨区域传输);
验证流程:采用纵向联邦学习,VPP A提供“负荷数据”,VPP B提供“历史竞价数据”,联合训练XGBoost竞价模型,模拟电力现货市场竞价,记录中标率与收益,检测数据隐私泄露风险,输出“竞价效果报告+合规性证明”。
- 场景3:跨区域VPP协同调度(2个跨省VPP,含新能源与电网数据)
验证目标:①隐私保护(各VPP本地电网规则、消纳率数据未共享,仅传递调度策略参数);②协同效果(跨网余电调配网损较单VPP调度降低≥5%);③鲁棒性(某VPP离线时,联邦模型仍能维持80%以上精度);
验证流程:采用联邦强化学习,各VPP本地训练调度策略模型,上传策略梯度至中心,中心聚合后下发全局梯度,模拟跨网余电调配场景,测试网损与模型容错性,输出“协同调度报告+鲁棒性测试日志”。
(3)未来拓展方向
- 与“数字孪生”结合:在虚拟环境中模拟联邦学习训练过程(如数据分布不均、节点离线等场景),优化聚合算法与参数更新频率,降低物理系统试错成本;
- 与“量子加密”联动:将量子加密技术应用于联邦学习参数传输(如用量子密钥加密模型参数),进一步提升隐私保护等级,解决高敏感场景参数传输风险的问题,形成“联邦学习+量子加密”的双重隐私防护体系。